
Eclipse Talks
The Fallacies of AB Testing
Ellie Hughes
Director
In AB testing, there are lots of mistakes we've all made when trying to make a programme successful.
Were your ideas high enough quality?
Did you have too few or too many?
What really is a good idea?
The planning of good experimentation is not easy - we'll explore three of the Ideation Fallacies, and provide some solutions we know work.
Next, we'll step into the world of Frequentist Statistics and bust three of the typical myths of statistics: counter-intuitive nature of running experiments for long enough, with the right data and not invalidating your experiment results.
Finally - we propose a Value Model which shows you an ideal way to think about the trade-off between Experiment Velocity vs Experiment Value.
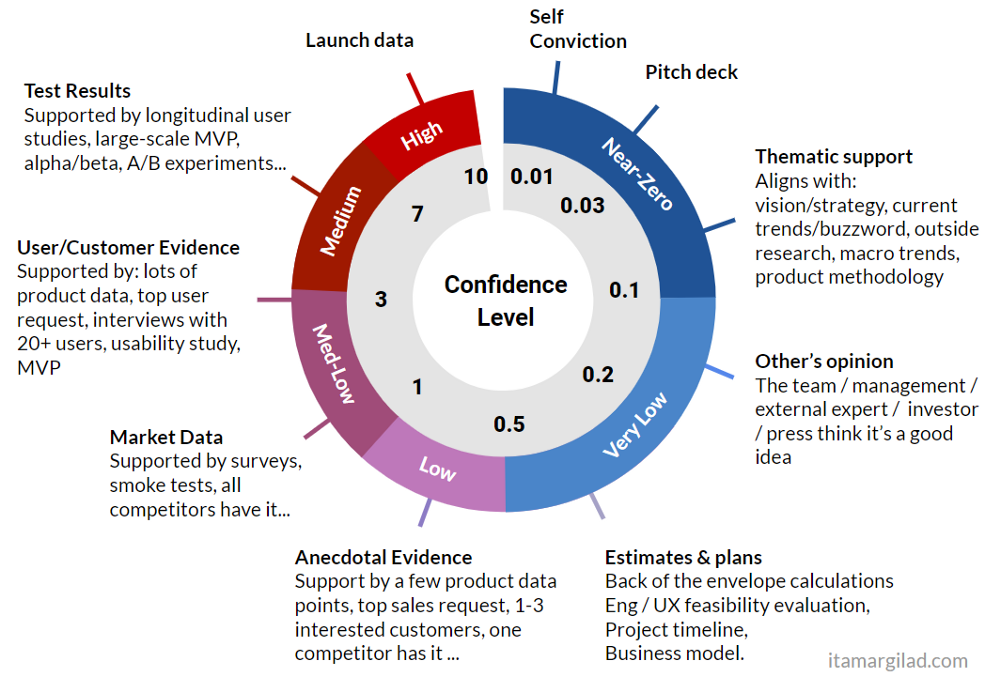
The Ideation Fallacies
Fallacy 1: It's easier to prioritise the "best" idea with more ideas
People mistakenly believe the correct approach is to create a backlog of all possible experiments, prioritise and then execute!Fallacy 2: You can deliver everything and the more you deliver the better
People mistakenly believe the more AB tests run, the better the programme.Fallacy 3: You can prioritise anything if you try hard enough
People mistakenly believe you can always use a framework to prioritise experiments e.g. RICE, ICE, PIE.
The following resources related to Fallacies 1-3, and each one focusses on a solution to help you overcome these very typical mistakes made in experimentation programmes everywhere.
These authors have run programmes themselves and speak with a wealth of product expertise.

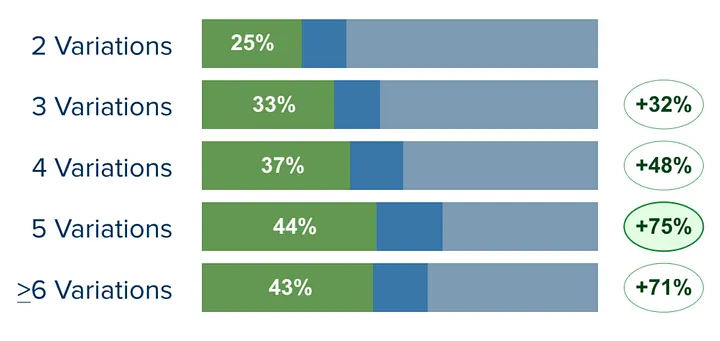
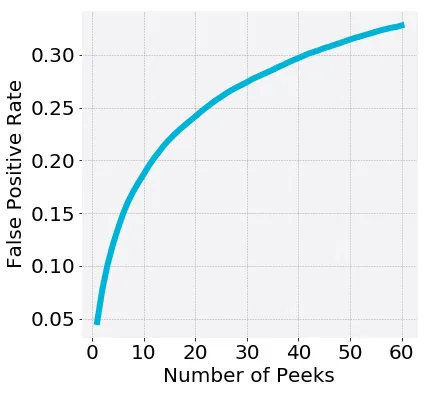
The Statistical Fallacies
Fallacy 1: Looking at results early (or peeking)
People mistakenly believe it is possible to interpret the experiment results or the statistical confidence throughout the experiment duration.Fallacy 2: The higher the confidence, the more confident I can be
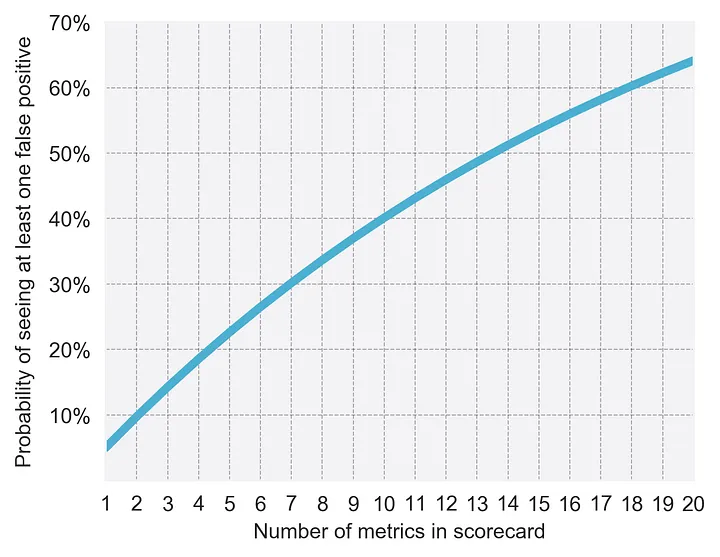
People mistakenly believe the statistical confidence value indicates how confident they can be in the results and the more data they collect, the more this value will keep going upFallacy 3: All metrics, and segments, are created equal
People mistakenly believe after an experiment runs, they can analyse any and all metrics and segments equally, and expect good results
The following resources related to Fallacies 1-3, and each one focusses on a solution to help you overcome these very typical mistakes made in experimentation programmes everywhere.
These authors have run programmes themselves and speak with a wealth of product expertise.
Resources

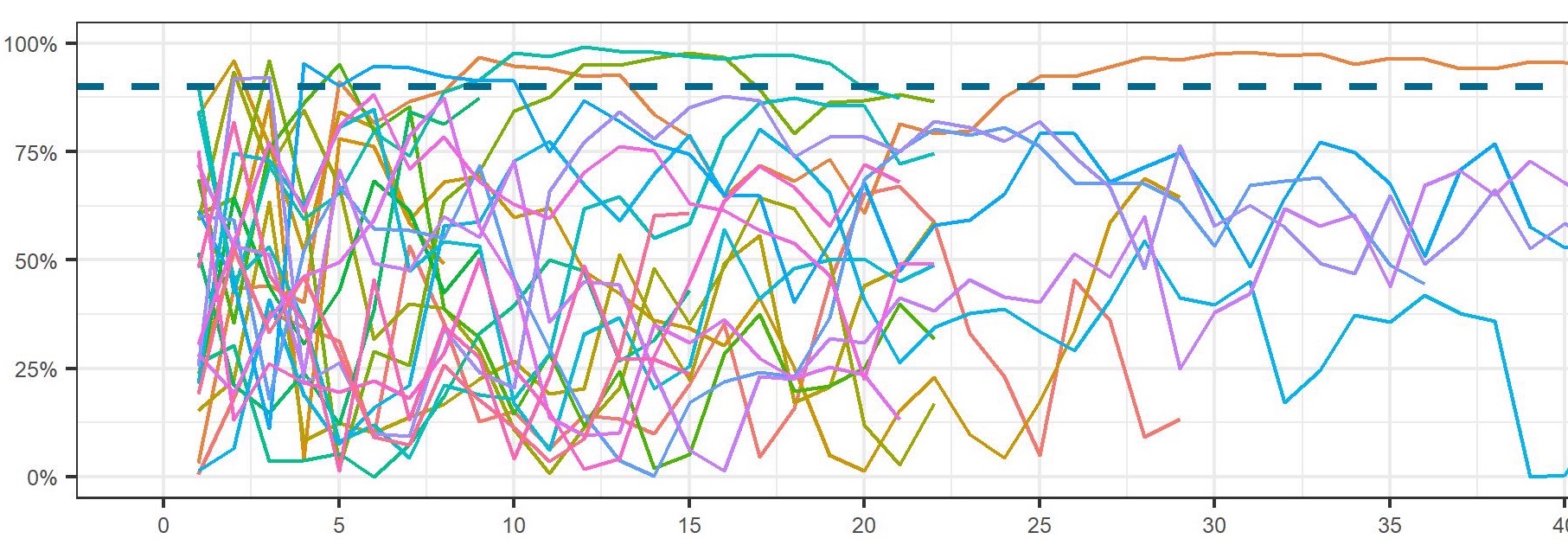
Value Model: How to think about experiment value
.png)
Three teams start working on different complexities of experiments for their experimentation.
The more complex experiments typically lead to higher lift values.
The complex experiments take longer to design, build and test: —> the team running more complex experiments does fewer experiments per month.
- Team 1: Attempts Highly Complex tests, Achieving 10% Uplift, and Deliver 1 Experiment per month
- Team 2: Attempts Medium Complexity tests, Achieving 4% Uplift, and Deliver 2 Experiments per month
- Team 3: Attempts Low Complexity tests, Achieving 1% Uplift, and Deliver 4 Experiments per month
.png)
.png)
Summary of solutions
Don’t get paralysed by prioritisation - embrace the possibility you might get it wrong but you will learn!
Be open to pivoting away from an idea when you get new evidence
Check your stats! Then check them again!
Finally, think about how you can optimise for value vs velocity - what is the version of this model that work for you?
The Fallacies of AB Testing - Product Tank
Here you can watch Ellie deliver this talk while at Product Tank, in front of an audience of 600 product people.
About Ellie
.webp)
If you enjoyed Ellie's talk or are making use of the resources here and want to know how you can implement them, please get in touch: connect with Ellie on Linkedin or use our contact form.
Ellie has over 13 years experience in the data and experimentation industry. In that time, she has helped businesses to ship experiments at scale, grow their data and product capability and create more value from their experimentation programme. She is the Director at Eclipse, an experimentation-focussed agency in the UK.